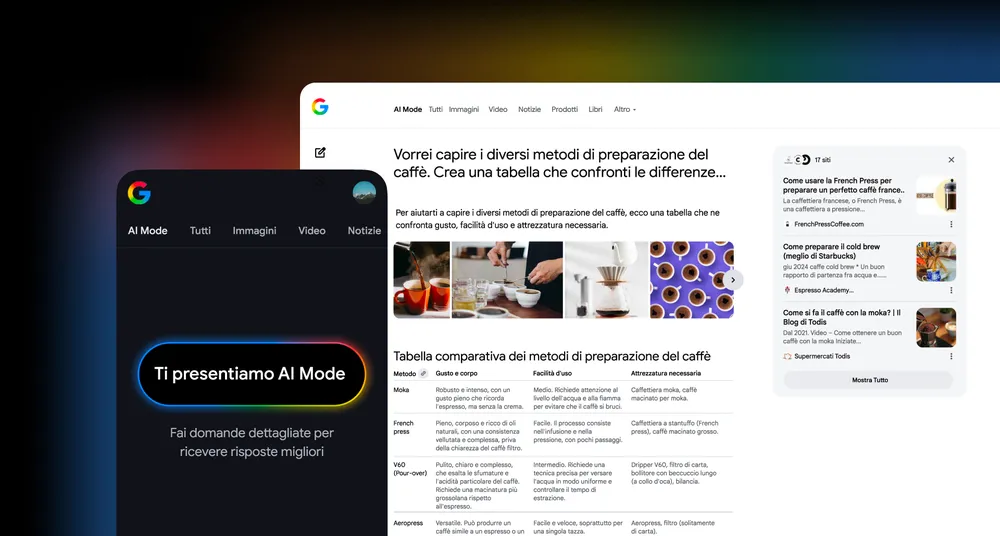
I modelli di intelligenza artificiale stanno crescendo talmente in fretta che i dati disponibili per addestrarli si sono già esauriti. Lo pensa Neema Raphael, responsabile dell’ingegneria dei dati di Goldman Sachs, intervenuto al podcast “Exchanges” prodotto dalla banca statunitense.
Raphael fa riferimento all’insieme dei dati “liberamente accessibili”, come ad esempio quelli presenti in rete. La fine dei dati accessibili avrà un impatto sul futuro sviluppo dell’AI, rendendo più complicato un miglioramento dei modelli nel breve-medio periodo. Tuttavia ci sono nuove frontiere di dati che non sono ancora state sfruttate, come quelli di proprietà delle aziende che operano in contesti molto specifici, che potrebbero presto tornare utili alle società di AI e migliorare la precisione e la conoscenza dei loro modelli.
Rapahel sottoliena inoltre che, per sopperire a questa scarsità, gli sviluppatori tendono ad addestrare i modelli su dati sintetici come testo, immagini e codice prodotti da altri modelli già esistenti. Secondo Raphael questo è un processo rischioso, perché sottoporre continuamente i modelli a dati artificiali può ridurre la loro qualità e di produrre nel tempo risultati sempre meno aderenti al mondo umano.

Molte big tech hanno usato illegalmente migliaia di video di YouTube per addestrare le AI
Un'indagine rivela che aziende AI come Apple o Anthropic hanno…